Alcune nazioni ci hanno dimostrato quanto possa essere utile tracciare i contagi da SARS-CoV-2 tramite app per smartphone.
L’approccio combina l’utilizzo di GPS e QR code per tenere traccia degli spostamenti di ogni singolo individuo e nel caso questo risulti, in un secondo tempo, positivo, avvisa (e richiede di sottoporsi a tampone) le persone che ne sono entrate in contattato stretto. Alle persone che sono entrate in contatto in modo meno diretto invece viene suggerito soltanto un approccio più ferreo al social distancing.
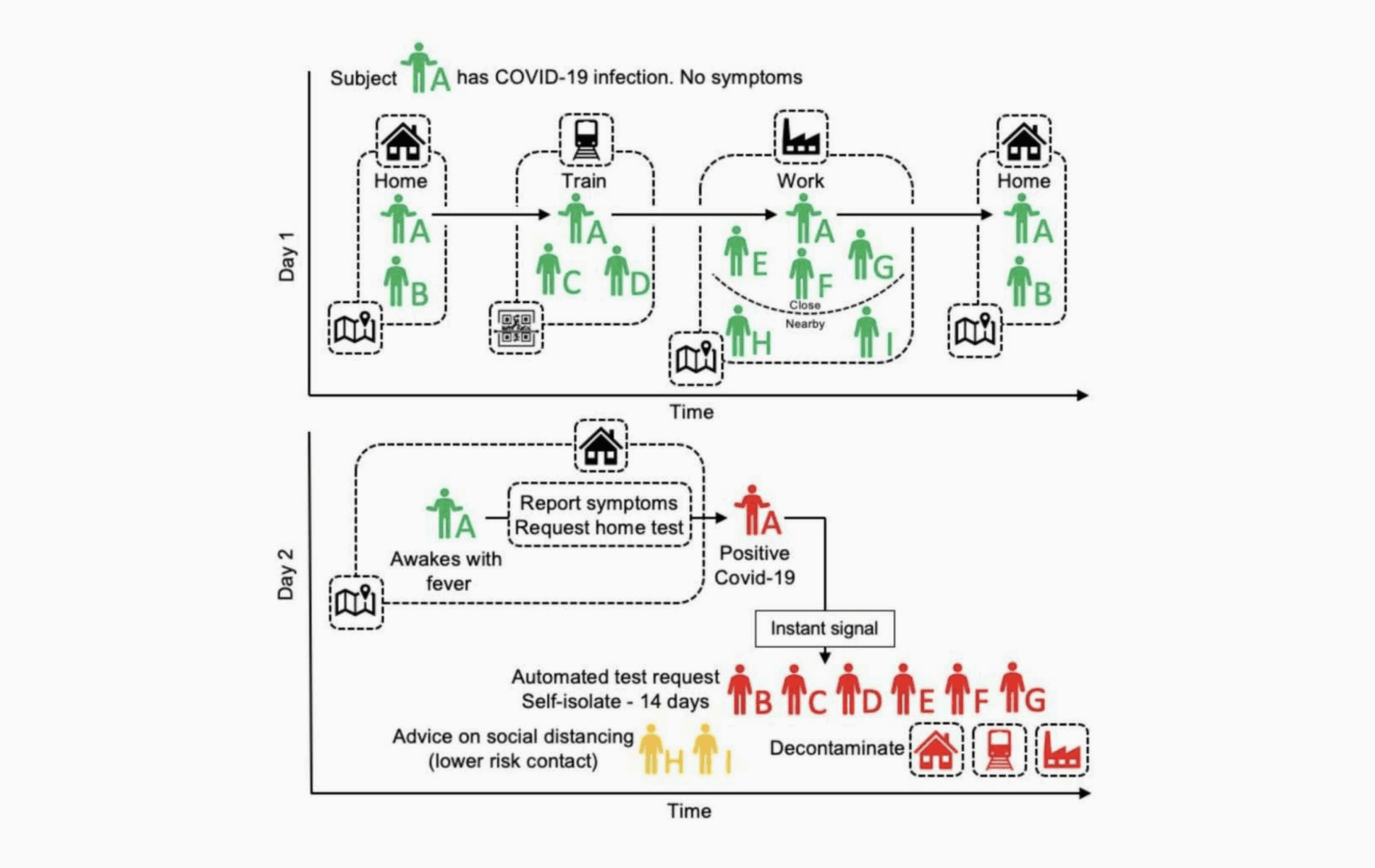
L’efficacia di questo metodo è evidente, basta una breve occhiata ai seguenti grafici:
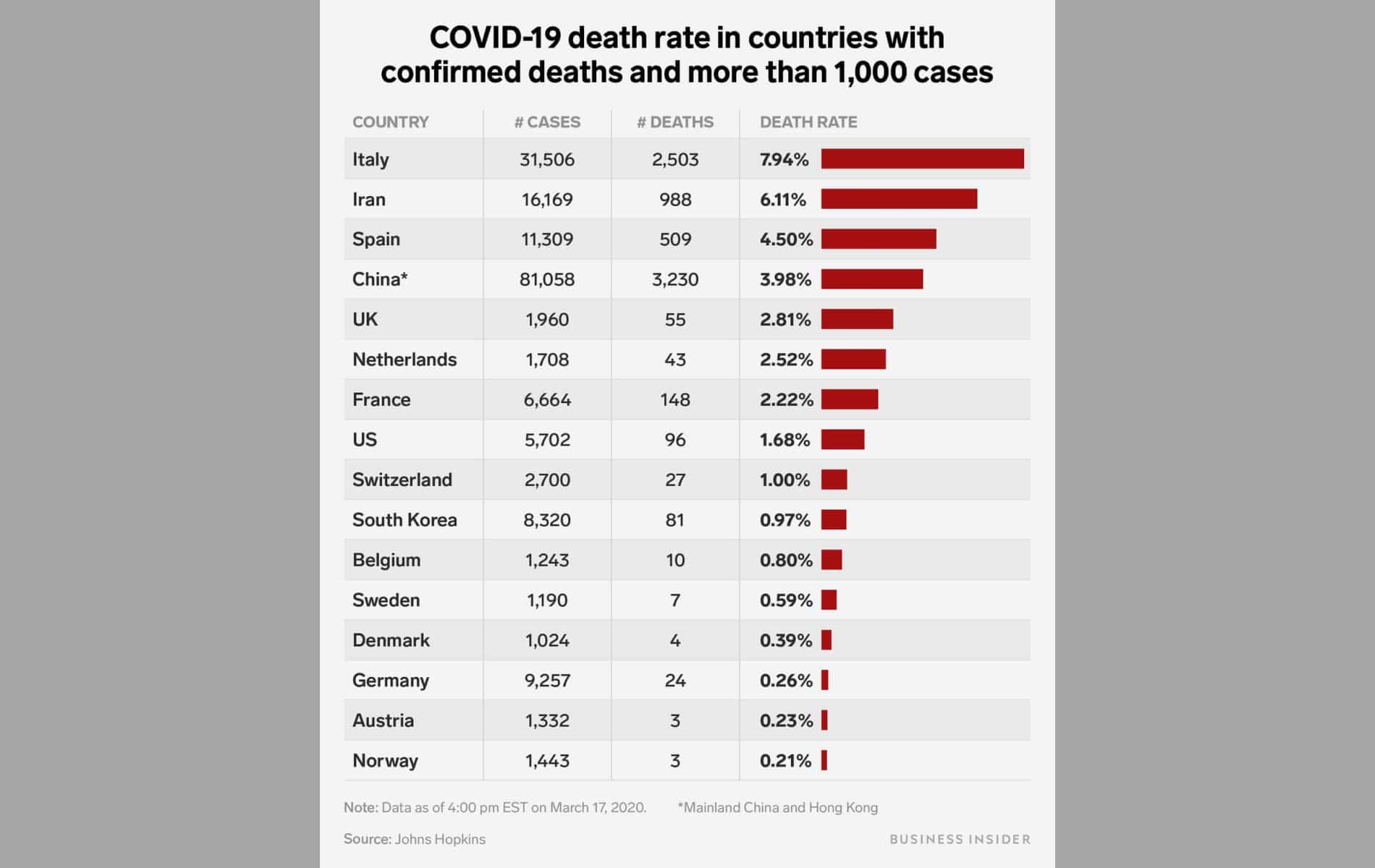
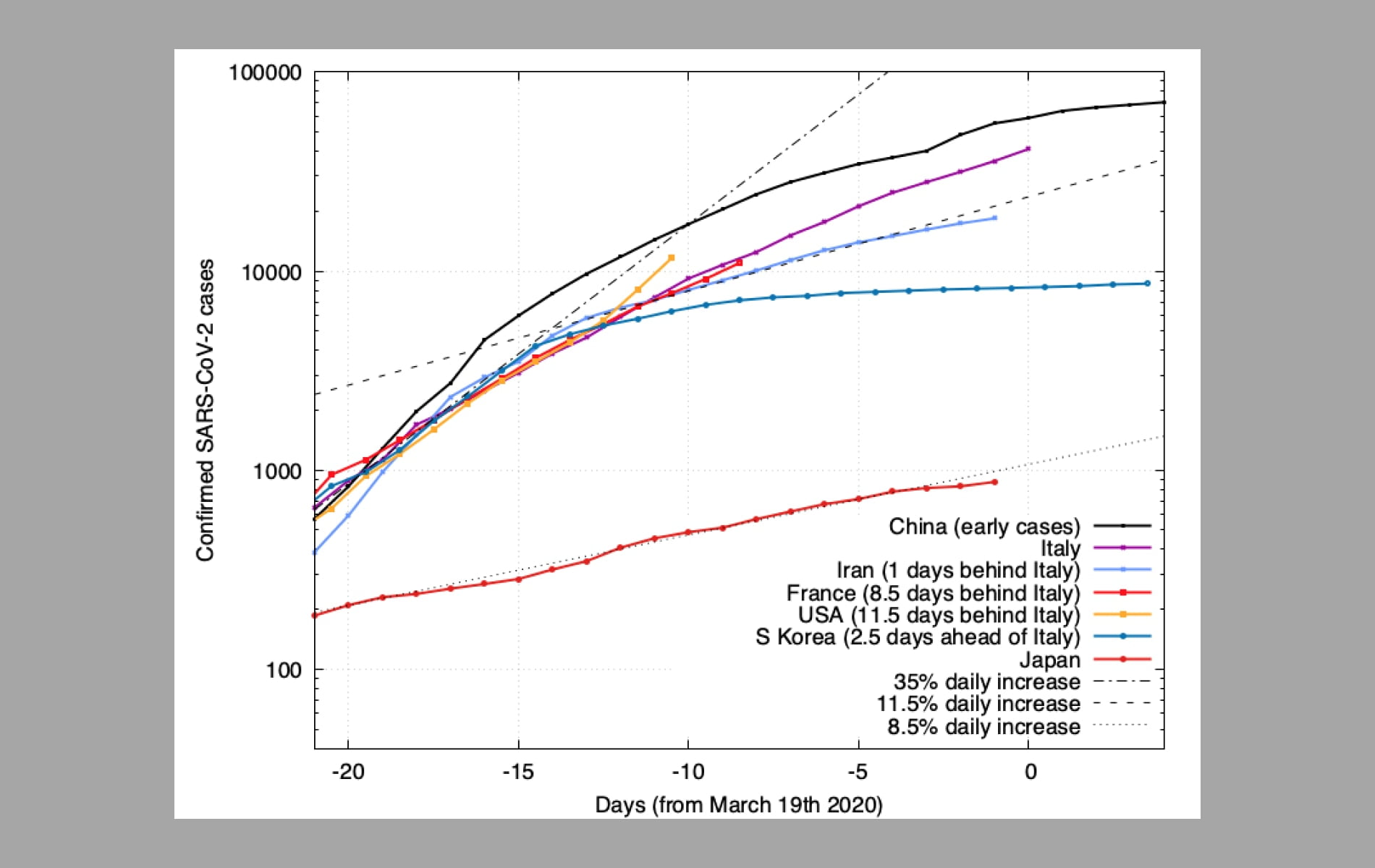
La Corea del Sud è riuscita ad appiattire la curva in modo efficace e ad individuare un altissimo numero di casi. Dividendo le morti su un così alto numero di casi la curva della letalità (il rapporto tra decessi e casi confermati) si appiattisce notevolmente: basta confrontare, nei dati disponibili fino al 18 Marzo, l’1% circa sudcoreano con il 7-8% circa dell’Italia. Non si tratta comunque degli unici fattori da tenere in conto: anche composizione demografica e fattori sociali giocano un ruolo molto importante.
In ogni caso, il problema di questo approccio è che risulta in netto contrasto con i regolamenti europei e americani per la protezione della privacy e siamo convinti che il diritto alla privacy sia effettivamente fondamentale.
Com’è quindi possibile ottenere gli stessi benefici senza mettere a rischio la privacy dei cittadini?
Un approccio rispettoso della privacy per tracciare i contagi
Abbiamo provato a darci una risposta, immaginando (un po’ per curiosità, un po’ come esercizio) le caratteristiche e problematiche che potrebbe avere un’app di tracciamento dei contagi che rispetti questi presupposti.
In primo luogo siamo convinti che i dati di geolocalizzazione debbano essere forniti in modo totalmente volontario: l’installazione dell’app può anche essere un requisito obbligatorio per permettere la rimozione di alcune delle limitazioni previste dall’attuale lockdown, ma l’invio di dati deve avvenire necessariamente sotto diretta volontà dell’utente.
I dati devono quindi risiedere fisicamente all’interno dell’applicazione e dello smartphone del cittadino e non essere in “cloud”: nella nostra ipotesi la posizione potrebbe essere registrata ad intervalli regolari (es. 5 minuti) e salvata in un database locale, creando così uno storico degli spostamenti preciso e affidabile, ma allo stesso tempo del tutto privato e non condiviso in alcun modo con alcun ente o istituzione.
Questi dati non ci serviranno per sempre: se consideriamo i 14 giorni massimi di incubazione del virus, sommati ad un cuscinetto necessario al manifestarsi dei sintomi più evidenti, al sottoporsi ad un tampone e all’ottenerne il risultato, l’arco di tempo da considerare assolutamente necessario si attesta quindi tra i 20 e i 30 giorni. Tutti i dati antecedenti possono essere eliminati senza rischi. (La valutazione esatta di questi tempi andrebbe ovviamente confermata da personale medico e adattata per nazione in base alla velocità e facilità di test).
Ci troviamo quindi con un’app che contiene circa 30 giorni di dati sui nostri spostamenti e nulla di più: come possiamo quindi passare da questo dato poco utile ad un sistema di notifiche?
Nel momento in cui un utente risultasse positivo a un tampone, verrebbe invitato a caricare i dati finora raccolti in un database condiviso in cloud (sempre in forma anonima e non liberamente consultabile): a quel punto un algoritmo confronterebbe i suoi spostamenti con quelli degli altri utenti, avvisando eventualmente le persone entrate in contatto col cittadino affetto dal virus.
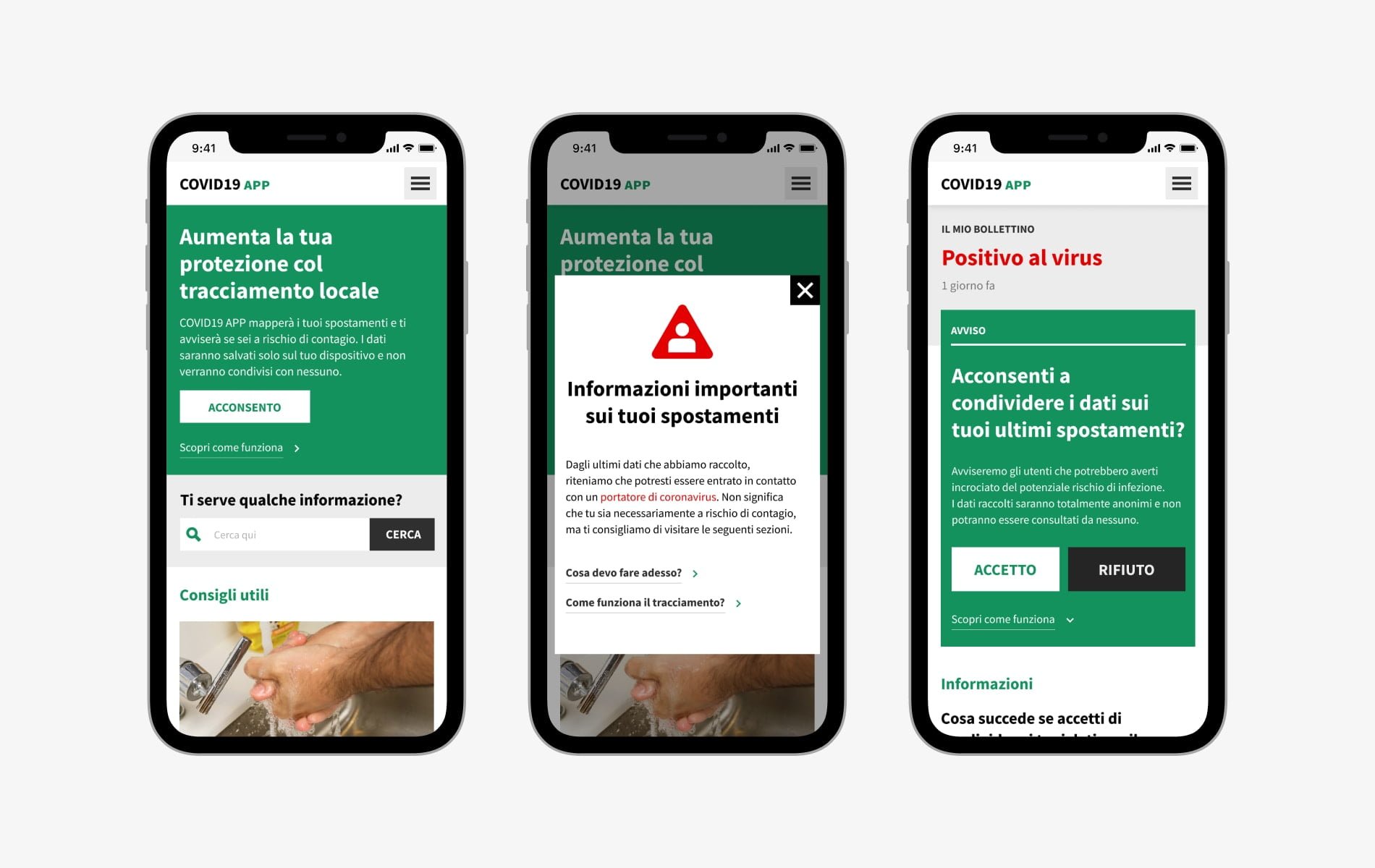
In Corea del Sud è stato adoperato un sistema simile, ma sono emersi comunque diversi problemi: ad esempio, anche se anonimi, i dati di un soggetto lasciano comunque delle “orme” facilmente riconoscibili, che in alcuni casi hanno permesso di riconoscere facilmente i cittadini malati (a volte con spiacevoli conseguenze).
Com’è quindi possibile evitare questa riconoscibilità?
Orme riconoscibili, ma non troppo
Per farlo dobbiamo rendere questi dati meno precisi, ma contemporaneamente, non possiamo permettercelo perché necessitiamo della massima precisione possibile per poter identificare l’avvenuto contatto tra due soggetti.
Partiamo quindi dal presupposto di rendere il dato meno preciso:
Precisione delle latitudini:
| DD.dddddd° | Decimal places | DD°MM′SS.sss″ | Metres |
| 1° | 0 | 1° | 111 120 |
| 0.1° | 1 | 0°06′ | 11 112 |
| 0.01° | 2 | 0°00′36″ | 1 111.2 |
| 0.001° | 3 | 0°00′03.6″ | 111.12 |
| 0.000 1° | 4 | 0°00′00,36″ | 11.112 |
| 0.000 01° | 5 | 0°00′00.04″ | 1.1112 |
| 0.000 001° | 6 | 0°00′00.004″ | 0.11112 |
Precisione delle longitudini:
| Precision of given longitude | Distance along a parallel depending on latitude | ||||||
| DD.dddddd° | Decimal places | DD°MM′SS.sss″ | 0° (equator) | 30° | 45° | 60° | 75° |
| 1° | 0 | 1° | 111 120 m | 96 233 m | 78 574 m | 55 560 m | 28 760 m |
| 0.1° | 1 | 0°06′ | 11 112 m | 9 623 m | 7 857 m | 5 556 m | 2 876 m |
| 0.01° | 2 | 0°00′36″ | 1 111.2 m | 962 m | 785 m | 555 m | 288 m |
| 0.001° | 3 | 0°00′03.6″ | 111.12 m | 96 m | 78 m | 55 m | 29 m |
| 0.000 1° | 4 | 0°00′00.36″ | 11.112 m | 9.6 m | 7.8 m | 5.5 m | 2.9 m |
| 0.000 01° | 5 | 0°00′00.036″ | 1.111 2 m | 0.96 m | 0.78 m | 0.55 m | 0.29 m |
| 0.000 001° | 6 | 0°00′00.003 6″ | 0.111 12 m | 0.096 m | 0.078 m | 0.055 m | 0.028 m |
Dobbiamo considerare che la densità di popolazione varia notevolmente tra i vari luoghi, che la precisione delle longitudini varia in base alla distanza dall’equatore e anche il concetto di privacy varia da paese a paese. I numeri di cui discuteremo saranno quindi soltanto un presupposto iniziale, da valutare con attenzione e da riadattare a seconda delle necessità.
Possiamo a nostro avviso considerare un buon livello di privacy una posizione con una precisione nell’arco dei 500m, ci risulta così che la precisione per la latitudine sia di circa 0.005° mentre quella per la longitudine vari tra 0.005° e 0.01° a seconda della distanza dall’equatore.
I dati di posizionamento ottenuti con questa approssimazione saranno quindi i dati pubblicabili in chiaro, rispettosi della privacy ma consultabili facilmente: quando un utente caricherà il proprio dato verrà approssimato a questi ordini di grandezza ed associato al timestamp (ora) corrispondente, verrà pubblicato in chiaro e gli altri utenti potranno scaricare soltanto i punti il cui raggio di approssimazione e orario ricada all’interno dei propri percorsi e hotspot.
A livello tecnico, l’app del soggetto sano interrogherà il server richiedendo punti “positivi” per finestre di spazio e tempo, rettangoli di grandi dimensioni (decine di km) su finestre orarie (range tra 1h-4h) per tutti i giorni precedenti (20-30gg come detto in precedenza). Per evitare di esporre i dati dell’utente sano, il server risponderà a ciascuna query soltanto con i valori la cui posizione approssimata risulti all’interno delle zone e fasce orarie richieste. Una volta ottenuti questi punti l’app li confronterà in locale per definire quali delle coordinate del soggetto sano ricadono all’interno delle zone di approssimazione dei soggetti “positivi”, scartando quindi i dati assolutamente non pertinenti.
Bene, a questo punto abbiamo quindi una serie di punti positivi nel raggio di circa 250m dalle posizioni del soggetto sano: decisamente troppo poco preciso per poter stimare, anche con molta approssimazione, se sia effettivamente avvenuto un contatto diretto. Come possiamo quindi mantenere il dato anonimo ma migliorare la precisione?
La crittografia come possibile soluzione
La crittografia unidirezionale può venire in nostro soccorso: possiamo crittografare il dato proveniente dal soggetto positivo con un livello sufficiente di precisione da stabilire se il contagio può essere avvenuto; va però tenuto in conto che il soggetto sano dovrà poter confrontare il proprio dato e quindi una precisione troppo elevata richiederà un maggior numero di confronti.
Facendo riferimento alle tabelle precedenti e considerando che la precisione del GPS non è assoluta, una precisione di circa 3m (valore da valutare ed eventualmente correggere a seguito di brevi test) potrebbe essere adatta per procedere con la nostra ipotesi. Risulta così che un’approssimazione di circa 0.00003° sia adatta per la latitudine mentre per la longitudine possa essere adatto un valore tra 0.00003° e 0.00006° a seconda della zona del mondo che stiamo andando a valutare.
I dati crittografati in questo modo sono abbastanza sicuri, perché come abbiamo detto non possono essere direttamente riconvertiti al dato in chiaro. Tuttavia, in linea teorica un soggetto “ostile” potrebbe comunque realizzare una rainbow table, cioè una tabella contenente tutti i valori possibili codificati con la stessa crittografia affiancati dal dato in chiaro, e risalire perciò al valore originale distruggendo così la privacy del soggetto.
La soluzione potrebbe consistere nell’inserire come seed l’orario, rendendo così il numero di valori troppo elevato per lo scopo (bisognerebbe infatti realizzare una tabella contenente tutti gli orari possibili per ciascuna combinazione possibile di latitudine e longitudine).
A questo punto quindi sarà possibile confrontare il nostro dato locale con il dato “positivo” preso da remoto e crittografato (che è quindi fornito assieme al dato approssimativo in chiaro e all’orario).
Si potrà quindi procedere con un sistema simile a una “battaglia navale” con 3 righe e 3 colonne (infatti abbiamo usato un’approssimazione 3 volte più precisa del necessario): prima di tutto dovremo prendere il nostro dato di posizione in chiaro, approssimato alla stessa maniera, e aumentarlo e diminuirlo di 1 unità di approssimazione in ognuna delle due dimensioni (latitudine e longitudine).
Otterremo così le coordinate dei nostri 9 quadretti della battaglia navale, che potremo crittografare con lo stesso orario del dato “positivo” ricevuto dal server (sempre approssimato allo stesso modo se approssimato).
Il risultato saranno così 9 stringhe crittografate, se almeno una di queste corrisponderà allora il contatto sarà avvenuto.
Ma un contatto così breve è al sicuro da falsi positivi? No, probabilmente non lo è, la cosa migliore sarebbe calcolare uno score sul numero di “match” avvenuti (considerando il fattore temporale, un match può avvenire anche più volte nello stesso luogo a distanza di 5 minuti ad esempio): più ne si riscontrano e più è alta la possibilità che ci sia stato un contagio. Ovviamente spetterà ad una commissione medico-scientifica valutare quale numero di match sia da indicare come probabile contagio e quale sia invece solo da avvisare con un “resta a casa”.
Si potrebbe anche valutare di segnalare a chi ha spesso incroci che non si convertono in match di fare più attenzione (persone che entrano spesso nel raggio di 500metri da un “positivo” ma non entrano mai in contatto stretto), ma sono decisamente aspetti che esulano dalle nostre capacità e competenze.
Questo metodo individuerà ogni singolo caso e risolverà totalmente il problema?
Assoutamente no: questo sistema, che è volutamente solo un esercizio di immaginazione, presenta diversi punti deboli (come si comporterà in luoghi con scarsa ricezione, o quando gli utenti viaggiano su mezzi di trasporto particolarmente veloci?).
Quel che è sicuro è che per fronteggiare al meglio gli effetti di questa pandemia bisognerà trovare una soluzione diversa dal tracciare i casi completamente alla cieca, permettendo di interrompere la catena di contagio dove è più necessario e di identificare anche i casi più “sfuggenti” (tra cui gli stessi asintomatici).
